
Real-Time Analytics and MongoDB

There seems to be a popular belief among engineers that Real-Time Analytics is a good use case for MongoDB. While there are legitimate reasons to believe so, the overall usage needs a deeper understanding.
The Problem
An analytical system needs to ingest data at a high rate. This requires the storage system to have low write latency and high throughput.
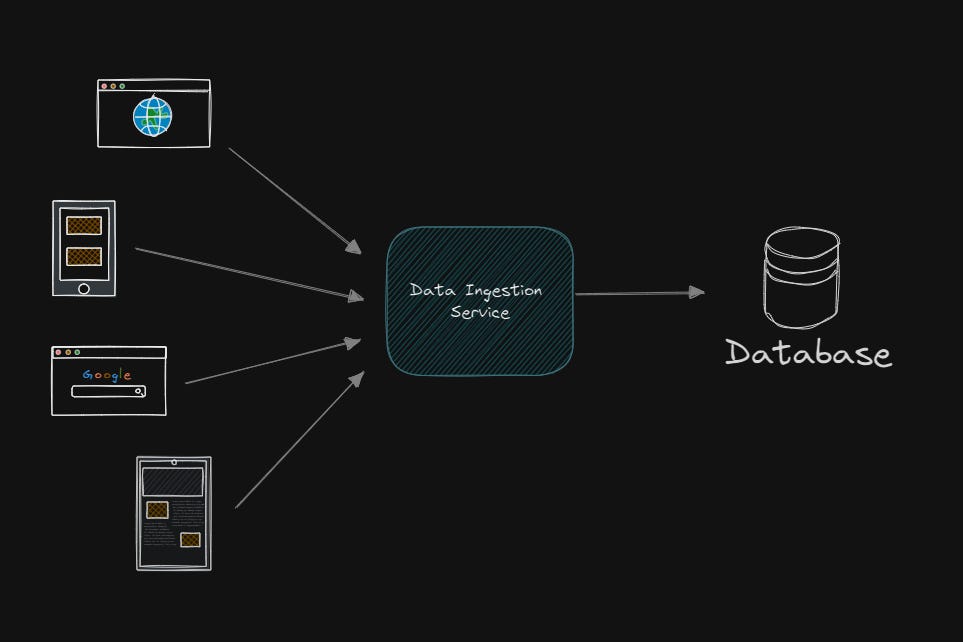
MongoDB is not always the best choice for write-heavy systems compared to other NoSQL databases like Cassandra or ScyllaDB. Here are some challenges:
📌 Challenges of MongoDB in Write-Heavy Systems
Write Performance: MongoDB’s default write operations are not as optimized for high-throughput writes as some other NoSQL databases. Databases like Cassandra and ScyllaDB offer better performance for write-heavy workloads due to their design, which allows for low-latency writes and linear scalability across nodes.
Clustering Costs: Managing a sharded MongoDB cluster can become costly. Sharding requires not only data but also indexes to be duplicated across shards to ensure proper performance and consistency during queries. Each shard holds its own copy of the index, increasing storage and resource consumption.
Critical Shard Key Selection: Choosing the right shard key is essential in MongoDB. A poorly chosen shard key can lead to hot spots, uneven distribution of data, or poor performance as some nodes may be overloaded while others remain underutilized.
📌 Could MongoDB be a Good Fit for Read-Heavy Analytics?
Yes, using MongoDB for storing processed data can work well in a read-heavy real-time analytics system, but pairing it with a write-optimized system can balance the workload.
🔹 Kafka or Scylla for Write-Heavy Systems:
Kafka or Scylla could handle high-throughput writes and act as a buffer, ingesting data in real-time. Kafka would be useful for stream processing, and ScyllaDB could store low-latency, write-heavy data due to its high performance in write operations.
🔹 MongoDB for Processed Data Storage:
Once the data is processed (aggregated, cleaned, transformed), you can store it in MongoDB for real-time querying and analysis. MongoDB excels in complex queries and can efficiently handle real-time analytics workloads when the focus shifts from writing to reading large volumes of data.
The Proposal
👉 Let’s dive deeper into a hybrid architecture combining Kafka, ScyllaDB, and MongoDB for handling high-throughput, low-latency writes while optimizing for real-time analytics.
📌 Proposed Architecture Overview
The architecture focuses on decoupling the write-intensive and read-intensive components to optimize both data ingestion and real-time analytics.
1. Data Ingestion Layer with Kafka
At the heart of this architecture is Apache Kafka or a similar message queue system that can act as a real-time data ingestion layer. Kafka ensures that incoming data is reliably captured and distributed to downstream components.
🔹 Kafka’s Role: Kafka can buffer and stream real-time data from various sources (e.g., user activity, sensor data, logs) while allowing multiple consumers to process this data in parallel. Its ability to handle millions of writes per second makes it an ideal fit for high-throughput applications.
🔹 Advantages:
Low Latency: Kafka provides real-time message delivery with low overhead.
Fault Tolerance: Kafka is highly reliable and can ensure that no data is lost even when downstream systems are under load.
Horizontal Scalability: Kafka brokers can be scaled horizontally to match increasing data volumes.
🔹 Example Use Case:
For a real-time IoT system, Kafka can collect data from thousands of sensors streaming in real-time, such as temperature, humidity, and device statuses.
2. Write-Heavy Data Store with ScyllaDB
Once Kafka ingests data, the raw, unprocessed data needs to be stored in a write-optimized NoSQL system. This is where ScyllaDB (or Cassandra) comes in. ScyllaDB is a powerful NoSQL database designed for low-latency, high-write performance, perfect for write-heavy workloads.
🔹 Why ScyllaDB (or Cassandra):
Low-Latency Writes: ScyllaDB’s design supports high throughput with low-latency writes, perfect for rapidly incoming data from Kafka.
Linear Scalability: ScyllaDB is known for its linear scaling, meaning that adding more nodes will proportionally improve the performance of writes and reads.
Automatic Data Replication: ScyllaDB automatically handles replication and fault tolerance, ensuring your data is safe and consistent across multiple nodes.
🔹 Architecture:
Kafka Consumers: A set of consumers reads messages from Kafka and writes them to ScyllaDB in real-time.
Time-Series Data: ScyllaDB excels at time-series data, where each incoming data point (e.g., from IoT sensors) is written as a new record.
🔹 Example Use Case:
In a real-time analytics system for a ride-hailing service, ScyllaDB can store raw trip data (e.g., location updates, timestamps) from millions of drivers and riders. It’s write-intensive, but it doesn’t require real-time querying just yet.
3. Real-Time Analytics with MongoDB
Once data is stored in ScyllaDB, it can be processed (aggregated, cleaned, transformed) and then passed to MongoDB, which acts as the read-optimized store for real-time analytics. This is where MongoDB’s strength lies—complex, flexible querying and serving real-time insights.
🔹 Why MongoDB:
Schema Flexibility: MongoDB allows developers to store processed data in a flexible schema, making it ideal for evolving business needs.
Rich Querying: MongoDB’s aggregation framework is powerful, enabling real-time insights by executing complex queries, filtering, and grouping operations.
Scaling Reads: MongoDB can efficiently scale horizontally to handle heavy read loads, which is critical for real-time analytics.
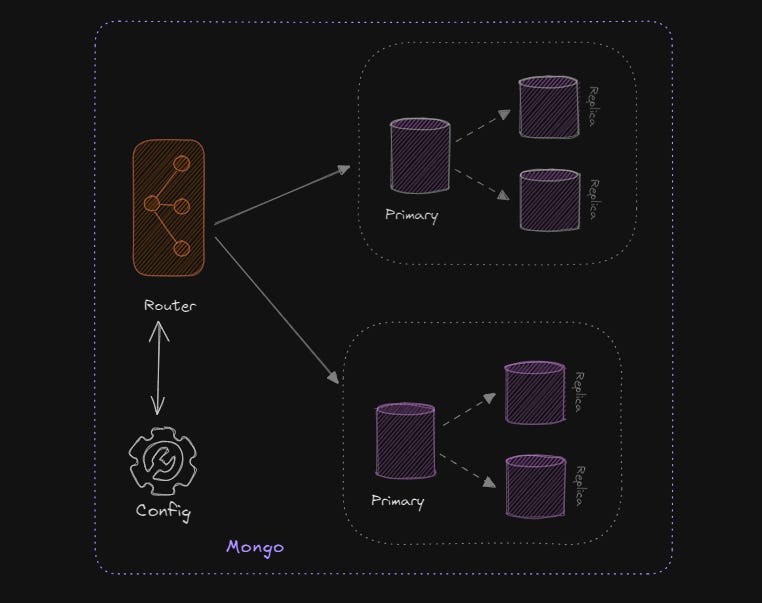
Indexes: MongoDB’s powerful indexing system supports fast querying. However, index duplication in sharded clusters can increase resource usage, so careful consideration of index design and shard keys is essential.
🔹 Sharding and Indexing:
MongoDB uses sharding to distribute large datasets across multiple nodes. But each shard holds its own index, which duplicates storage and indexing overhead.
The shard key is critical—choosing the right shard key affects both performance and distribution of data across nodes.
🔹 Example Use Case:
For the same ride-hailing service, MongoDB can store processed trip data such as total distance, fare, driver ratings, and customer feedback. The aggregation of this data could provide real-time insights such as average trip length, busiest times of day, or heatmaps of ride demand.
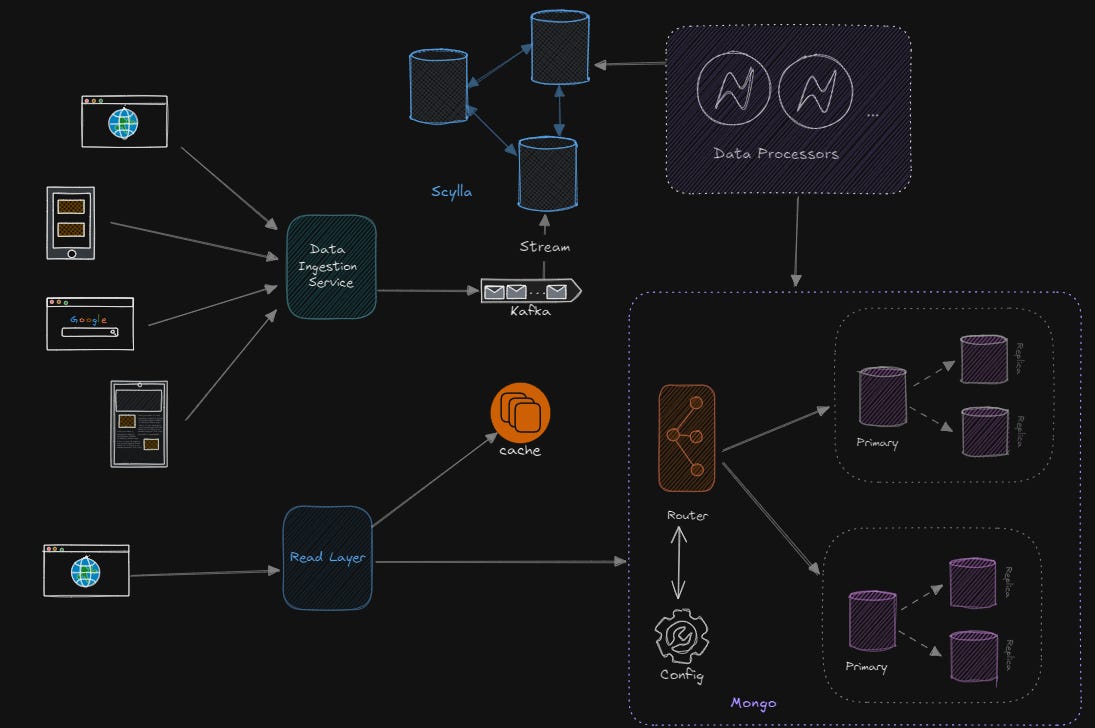
📌 The Role of Each Component
1. Kafka (Data Ingestion):
Kafka ingests real-time streaming data (e.g., logs, sensor data, app activity) and acts as the intermediary between the write-heavy store and processing layer. Kafka scales horizontally to handle high throughput and ensures no data is lost under heavy load.
2. ScyllaDB (Write-Optimized Store):
ScyllaDB is the system of choice for handling low-latency, write-heavy workloads. It acts as a scalable time-series store for unprocessed data that needs to be written at high speed. While MongoDB would struggle with this volume of writes, ScyllaDB excels here.
3. MongoDB (Read-Optimized Analytics):
Once the data is processed, MongoDB provides a read-optimized storage layer that supports flexible schema changes and complex queries, ideal for real-time analytics. It scales horizontally to handle massive datasets for fast, real-time querying.
📌 Architecture Flow Example:
Data Ingestion: Real-time data from IoT devices, apps, or logs flows into Kafka.
Low-Latency Writes: Kafka streams the raw data into ScyllaDB, where it is stored and partitioned based on time, location, or other business-specific criteria.
Processing Layer: A data processing layer reads data from ScyllaDB, processes it (e.g., aggregates, cleans, transforms), and passes the results to MongoDB.
Real-Time Analytics: MongoDB stores the processed data and provides real-time insights via its rich querying and aggregation framework. Dashboards, analytics platforms, and apps pull data from MongoDB to display insights.
📌 Advantages of This Hybrid Setup:
🔹 Decoupling Write and Read Workloads:
By splitting write-heavy and read-heavy operations between ScyllaDB and MongoDB, the architecture ensures that each database handles the workload it’s optimized for.
🔹 Kafka’s Buffering Capabilities:
Kafka acts as a buffer, making the system more resilient to spikes in traffic, ensuring that the databases can ingest data at their own pace.
🔹 Scalability:
Both ScyllaDB and MongoDB are designed for horizontal scalability, making it easier to scale the system as data volumes grow.
🔹 Optimized Costs:
MongoDB clustering is costly, especially when handling high write volumes. By offloading writes to ScyllaDB, you reduce MongoDB’s storage and processing burden, which can significantly cut down on operational costs.
📌 Challenges to Consider:
Data Synchronization:
You’ll need an efficient processing pipeline between ScyllaDB and MongoDB to ensure that data is processed and synced in near real-time.Shard Key Design:
Choosing the right shard key in MongoDB is critical. Poor shard key selection can lead to uneven data distribution or “hotspots,” which can degrade performance.Operational Complexity:
Managing multiple database systems increases the operational overhead. Ensuring seamless integration and monitoring between Kafka, ScyllaDB, and MongoDB will require careful planning and tooling.
📌 Conclusion
This hybrid architecture provides a balance between low-latency writes (with ScyllaDB) and real-time analytics (with MongoDB), powered by Kafka for reliable data ingestion. This approach maximizes performance while managing the cost and complexity associated with MongoDB clustering.
👉 For mid-size systems introducing ScyllaDB might be overkill. Kafka itself, with its fanout consumer proxy pattern, can be enough to handle a considerable amount of data processing.