


System Design: Uber Part 1
Design a ride-hailing service like Uber, Lyft, OLA etc.

What is Uber?
Uber is a mobility (transport) service provider. It connects end-users with the best possible (cost, time, preference, etc.) nearby cab, auto, etc. drivers (transport providers), allowing users to book a ride from source to destination on their mobile phones.
Requirements
Requirements can be divided into functional and non-functional requirements as below:
Functional Requirements
FRs help in identifying NFRs and hence we will start with FRs. We see two different categories of users in the system - Drivers (Transport Providers) and Customers (persons booking the transport).
As the customer is King 🫅, we will start with customers.
Customers
Customers should be able to see different transports available nearby with an expected time of arrival post booking (ETA), driver ratings, and pricing information. For brevity we will consider only 1 type of cab as transport for initial discussions, more types can be added later.
Customers should be able to search for destinations using auto-complete.
Customers should be able to book a cab to their chosen destination. We are initially considering intra-city/region transport.
Customers should be able to track drivers’ movement (location) after successful booking.
Customers should be able to send additional information via text messages to the allocated driver.
Customers should be able to call the allocated driver.
Customers should receive OTP to verify the ride and start the journey.
Drivers
Drivers should be able to accept or deny the ride request.
Once a ride is accepted, the driver should receive the customer’s pickup (source) location.
Drivers should be able to key customers’ OTP to verify and start the ride.
Drivers should be able to mark the trip as completed.
Now, while we identified two main categories of users in our system we missed the other important system entity and its sub-entities that make the connectivity possible. Yes, the Uber System.
Uber
The system must receive drivers’ current location information in a near-real-time manner.
The system should be able to suggest routes to transport Customers and Drivers and provide a UI (user interface) and voice support for detailing the routes.
These two requirements are essential for a safe riding experience and provide seamless connectivity between customers and drivers.
Non-Functional Requirements
Latency
Reliable
The design should ensure that the system is fault-tolerant and recoverable within acceptable time frame.
High Availability
Elasticity - should be able to scale out and in.
Cost Efficient
WebSocket session management and notification center
Client and Server-side WebSocket load balancing
Adding to NFRs
Not every scenario needs ultra-low latency but there are cases where latency would matter.
Auto-complete/suggest for location search should be fast.
Finding drivers in the vicinity and calculating prices should be fast.
While booking the focus is on consistency and merging two distributed events i.e. The book event is initiated by the customer and then needs to be accepted by the driver.
A driver may or may not accept the booking and thus we may want to send the request to multiple drivers (Multicast).
To identify multiple drivers in the vicinity all the drivers must keep sending the heartbeat at a low frequency. This will be a write operation at a high scale; thus, it must finish fast.
Once the data is received, it should be processed in near-real-time. This is important to:
Implement Uber Pool as the driver could be moving.
Assign the next ride when the driver finishes the previous ride.
…
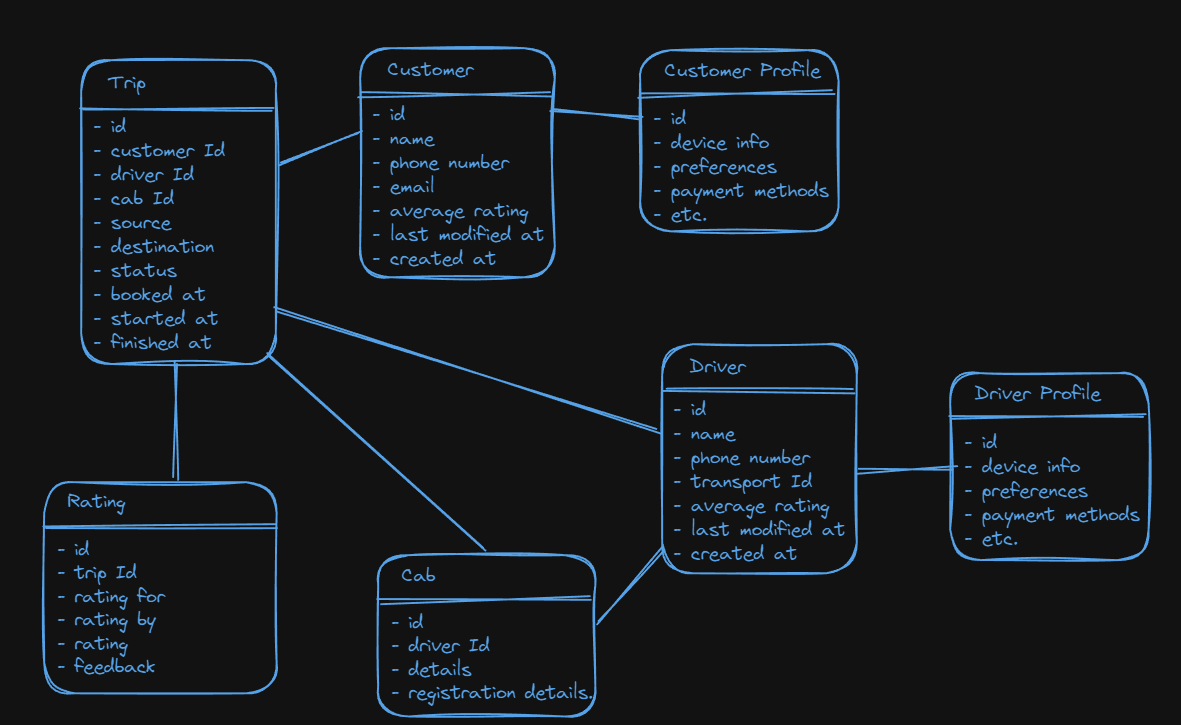
A high-level domain design
The core problem
Given the current location(latitude, longitude) of the user and radius, find the nearby entities. The radius can be increased in each step until the thrshold is reached or the nearby entities are found.
Using Geo-Spatial Databases / Indexes
Most of the databases provide Geo-Spatial Indexes which work on Lat, Lng. PostgreSQL, MySQL, ElasticSearch, Redis etc.
What is a Spatial (Geospatial) Database?
A spatial database also known as a “geospatial database” is built to capture and store the points, lines, and areas of location and is referred to as spatial data

Note: For simplicity ploygons, polylines etc. have been removed.
Spatial databases typically just compute a rectangle around each of the features in a dataset and use that as a rough index for queries. This is also known as a minimum bounding rectangle (MBR) and a type of R-Tree index is used too.
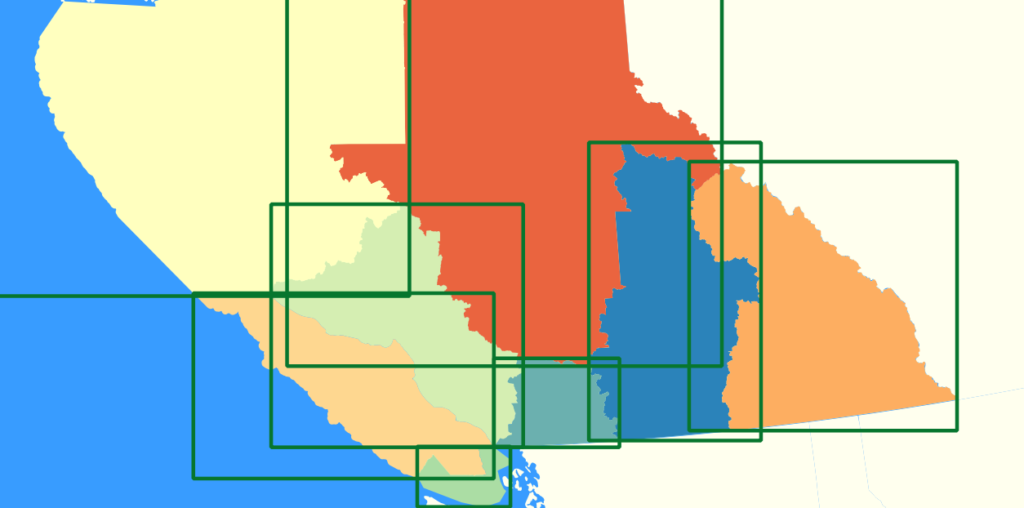
Querying data then uses these indexes to find the spatial features that overlap or are within a distance of another location. They use the MBR to see how close the features may be to one another so it can ignore ones that are not close enough to matter.
Types of Spatial Indexes
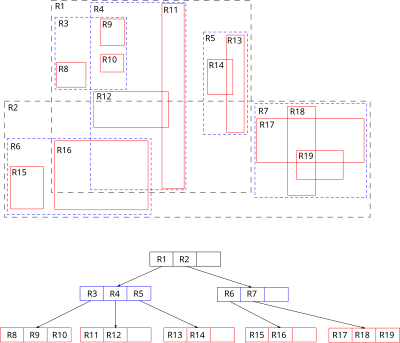
R-Tree:
Structure: R-trees are hierarchical structures that group spatial objects into bounding rectangles. Each node in the R-tree represents a bounding box that contains a collection of spatial objects.
Functionality: When a spatial query is executed, the R-tree allows the database to quickly eliminate large portions of the dataset by checking bounding boxes before performing more detailed geometric calculations. This two-pass approach improves query performance significantly.
Use Cases: R-trees are commonly used in geographic information systems (GIS) and for indexing multi-dimensional data.

Source: Wikipedia
Quadtree:
Structure: Quadtrees recursively subdivide a two-dimensional space into quadrants. Each node represents a quadrant and can contain one or more spatial objects.
Functionality: Quadtrees are efficient for spatial queries involving point data and can quickly narrow down the search area by traversing the tree structure.
Use Cases: They are particularly useful in applications like image processing and GIS.

Source: Wikipedia

There are other structures like K-D Tree etc.
Then what is the problem?
Radial spatial queries often involve complex geometric calculations, such as determining distances from a central point to various other points in the dataset. These calculations can be computationally intensive, especially when dealing with large datasets, as the database must evaluate the distance for each point in relation to the query's center. This generally results in high CPU and RAM utilization.
Most of the simpler solutions grow vertically and thus in certain cases require expensive hardware or complex sharding mechanisms.
The amount of data points that need to be stored to build a GIS system that can work at different zoom levels and provide high accuracy demands a huge amount of data. Trillions on record.
When the target entity is changing location, a lot of mutations (write) are required on the same database. Thus, the read and write latencies and throughput are critical here.
Consider a MySQL example
select name from places
order by st_distance(point(@lng, @lat), point(lng, lat))
limit 10This simple looking query uses a function named
st_distance. This function performs all the mathematical calculations.
What are other solutions?
Geo-Hashing
Geohashing is a geocoding system that converts geographic coordinates (latitude and longitude) into a short, alphanumeric string called a geohash. The main purpose of geohashing is to simplify the representation of locations and enable efficient spatial indexing and proximity searches.

The world is divided into a grid of rectangles, with each rectangle assigned a unique geohash code.
Geohashing uses a binary search approach to determine which half of a rectangle contains a given point. It assigns a binary digit of 1 for the upper half and 0 for the lower half.
The process of dividing the rectangle and assigning binary digits continues iteratively until the desired level of precision is reached. The resulting binary string is then converted into a base-32 representation using a character set of 0-9 and a-z (excluding i, l, o).
The length of the geohash string determines the level of precision. A shorter geohash represents a larger area, while a longer geohash represents a smaller and more precise area. For example, a geohash of length 5 might represent a region the size of a city, while a geohash of length 10 could pinpoint a location within a few meters.
Nearby geographic locations have similar geohash prefixes, which enables efficient proximity searches and spatial indexing. By comparing the prefixes of geohashes, one can effectively determine the proximity of two locations.
Geohashing offers several benefits:
Simplicity and versatility: Geohashing simplifies the representation of geographic coordinates into a compact, easy-to-use format.
Efficient spatial indexing: Geohashing allows for efficient indexing of spatial data, enabling quick retrieval and proximity searches.
Ease of implementation: Geohashing is relatively simple to implement compared to other spatial data structures.
Geo Hash Distance Metrics

S2 Library
The S2 library, developed by Google, is a powerful tool for spatial indexing and manipulation of geometric shapes on a spherical surface. Here’s a detailed overview of its features, structure, and indexing capabilities:
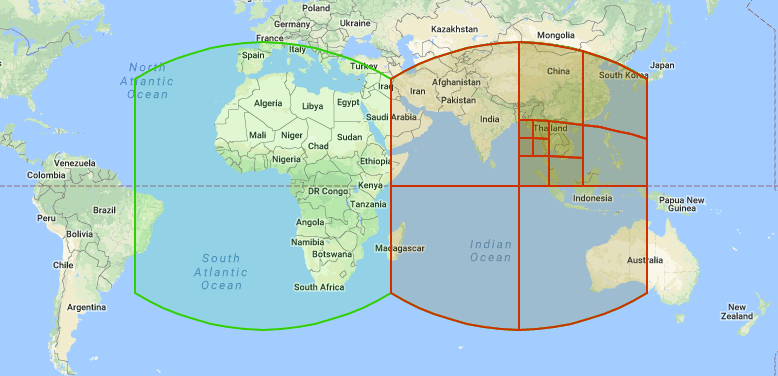
1. Spherical Geometry Representation
Unlike traditional geographic information systems (GIS) that represent data on a flat two-dimensional plane, the S2 library operates on a three-dimensional sphere. This approach allows for a more accurate representation of geographic data, minimizing distortion and enabling seamless global coverage.
2. Hierarchical Cell Structure
S2 uses a hierarchical decomposition of the sphere into discrete regions known as S2 cells. Each cell is represented by a 64-bit integer, allowing for efficient storage and indexing. The cells are organized in a way that:
They have varying levels of resolution, enabling efficient queries at different granularities.
Nearby geographic locations share similar prefixes in their geohash-like representations, facilitating proximity searches.
3. Hilbert Curve for Spatial Indexing
The S2 library employs a Hilbert curve, a space-filling curve that preserves locality. This means that points that are close together in two-dimensional space remain close together when mapped to one-dimensional space. This property enhances the efficiency of spatial queries, as nearby points can be indexed and retrieved quickly.
Indexing Capabilities
1. S2PointIndex
Purpose: This index is designed to manage collections of points on the sphere.
Functionality: It supports incremental updates and allows for efficient nearest-neighbor queries. For example, you can quickly find the closest points to a given target point.
S2PointIndex<int> index;
for (int i = 0; i < num_points; ++i) {
S2Point point = S2Testing::RandomPoint();
index.Add(point, i); // Add point with auxiliary data
}2. S2ShapeIndex
Purpose: This index is used for more complex geometries, including polylines and polygons.
Functionality: It supports various query types, such as checking if a point is contained within a shape, finding the closest edge to a point, and performing boolean operations (like intersection and union).
3. S2RegionTermIndexer
Purpose: This tool integrates spatial data into information retrieval systems.
Functionality: It allows the addition of S2 regions to documents, enabling queries to return documents that intersect with specified regions.
4. Efficient Query Operations
The S2 library provides efficient query operations for:
Finding nearby objects
Measuring distances between points
Computing centroids of shapes
Performing geometric operations like intersections and unions
Key Features of S2
Fast In-Memory Spatial Indexing: S2 enables quick access to collections of points, polylines, and polygons.
Robust Geometric Operations: The library includes functions for robust geometric operations, ensuring accuracy even with complex shapes.
Extensive Testing: The library has been extensively tested against Google’s vast geographic data, ensuring reliability and performance.
H3 Library
H3 is a hierarchical geospatial indexing system developed by Uber that uses a hexagonal grid to represent geographic locations. This approach offers several advantages in terms of spatial analysis, data aggregation, and efficient querying.

1. Hexagonal Grid Structure
H3 divides the Earth's surface into hexagonal cells, which are more efficient for spatial queries compared to traditional square grids. Hexagons provide better coverage and minimize distortion, especially in geographic applications.
Each hexagonal cell is identified by a unique 64-bit index, allowing for efficient storage and retrieval.
2. Hierarchical Indexing
H3 employs a hierarchical structure where each hexagon can be subdivided into seven smaller hexagons (children). This hierarchical relationship allows for varying levels of resolution, from coarse (level 0) to fine (level 15).
The hierarchical nature enables efficient aggregation and analysis of spatial data at different levels of granularity.
3. Resolution Levels
The resolution level determines the size of the hexagonal cells. Lower resolution levels cover larger areas with fewer hexagons, while higher levels provide more detailed coverage with smaller hexagons.
For example, at resolution 0, there are 122 hexagons, while at resolution 15, there are over 400,000 hexagons.
Key Features of H3
1. Spatial Queries and Proximity Searches
H3 allows for efficient spatial queries, such as finding nearby hexagons or checking if a point falls within a specific hexagon.
The hexagonal structure ensures that geographically close locations have similar index values, facilitating quick proximity searches.
2. Aggregation and Summarization
H3 supports data aggregation over hexagonal cells, making it suitable for applications like thematic mapping and spatial analysis. For instance, data points can be bucketed into hexagons to visualize patterns or trends.
3. Functions and Operations
H3 provides a range of functions for working with hexagonal indices, including:
h3ToParent: Returns the parent hexagon of a given index.h3ToChildren: Retrieves the child hexagons of a given index.h3IsValid: Validates whether a given index is a valid H3 index.h3GetResolution: Determines the resolution level of a given index.
4. Compact and Uncompact Cells
H3 allows for the compaction of contiguous sets of hexagons into a smaller representation, which can be useful for optimizing storage and reducing the number of cells processed in queries. The
compactCellsanduncompactCellsfunctions facilitate this process.
5. Geospatial Manipulations
H3 supports various geospatial algorithms, including nearest neighbor searches, shortest path calculations, and gradient smoothing, making it versatile for different applications.
Use Cases of H3
Location-Based Services: H3 is widely used in applications that require efficient spatial queries, such as ride-sharing, delivery services, and location-based advertising.
Data Visualization: The hexagonal grid structure is effective for visualizing spatial data in thematic maps, allowing for clear representation of aggregated data.
Environmental Monitoring: H3 can be used to analyze environmental data, such as air quality or wildlife tracking, by aggregating data points into hexagonal cells.